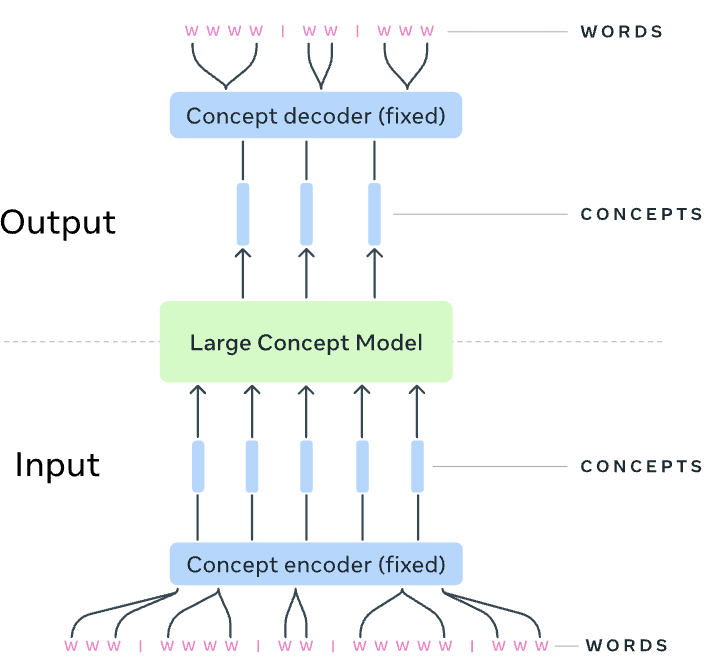
LLMs have revolutionized the field of artificial intelligence and have emerged as the de-facto tool for many tasks. The current established technology of LLMs is to process input and generate output at the token level. This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attempt at an architecture which operates on an explicit higher-level semantic representation, which we name a concept. Concepts are language- and modality-agnostic and represent a higher level idea or action in a flow. Hence, we build a "Large Concept Model". In this study, as proof of feasibility, we assume that a concept corresponds to a sentence, and use an existing sentence embedding space, SONAR, which supports up to 200 languages in both text and speech modalities. The Large Concept Model is trained to perform autoregressive sentence prediction in an embedding space. We explore multiple approaches, namely MSE regression, variants of diffusion-based generation, and models operating in a quantized SONAR space. These explorations are performed using 1.6B parameter models and training data in the order of 1.3T tokens. We then scale one architecture to a model size of 7B parameters and training data of about 2.7T tokens. We perform an experimental evaluation on several generative tasks, namely summarization and a new task of summary expansion. Finally, we show that our model exhibits impressive zero-shot generalization performance to many languages, outperforming existing LLMs of the same size. The training code of our models is freely available.
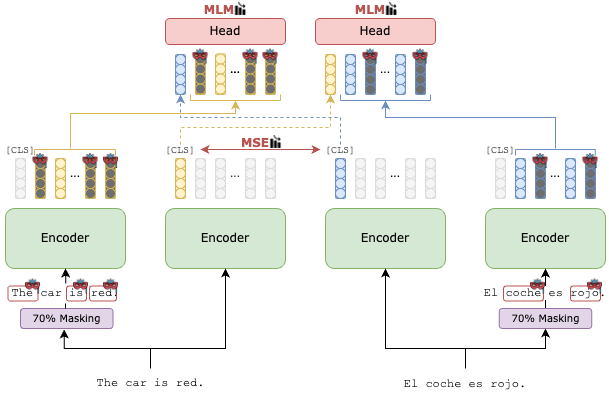
Current pre-trained cross-lingual sentence encoders approaches use sentence-level objectives only. This can lead to loss of information, especially for tokens, which then degrades the sentence representation. We propose MEXMA, a novel approach that integrates both sentence-level and token-level objectives. The sentence representation in one language is used to predict masked tokens in another language, with both the sentence representation and all tokens directly updating the encoder. We show that adding token-level objectives greatly improves the sentence representation quality across several tasks. Our approach outperforms current pre-trained cross-lingual sentence encoders on bi-text mining as well as several downstream tasks. We also analyse the information encoded in our tokens, and how the sentence representation is built from them.
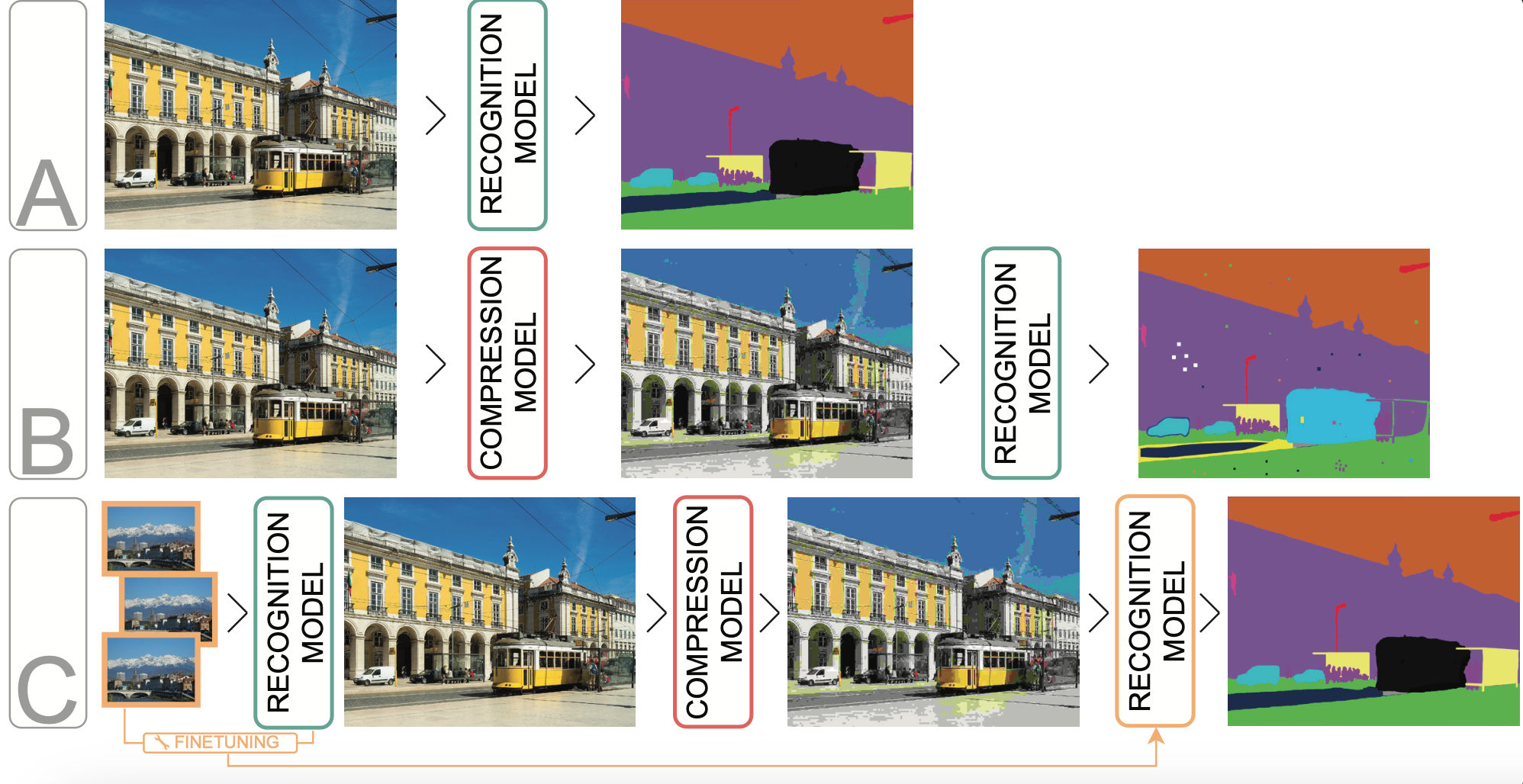
Reducing the data footprint of visual content via image compression is essential to reduce storage requirements, but also to reduce the bandwidth and latency requirements for transmission. In particular, the use of compressed images allows for faster transfer of data, and faster response times for visual recognition in edge devices that rely on cloud-based services. In this paper, we first analyze the impact of image compression using traditional codecs, as well as recent state-of-the-art neural compression approaches, on three visual recognition tasks: image classification, object detection, and semantic segmentation. We consider a wide range of compression levels, ranging from 0.1 to 2 bits-per-pixel (bpp). We find that for all three tasks, the recognition ability is significantly impacted when using strong compression. For example, for segmentation mIoU is reduced from 44.5 to 30.5 mIoU when compressing to 0.1 bpp using the best compression model we evaluated. Second, we test to what extent this performance drop can be ascribed to a loss of relevant information in the compressed image, or to a lack of generalization of visual recognition models to images with compression artefacts. We find that to a large extent the performance loss is due to the latter: by finetuning the recognition models on compressed training images, most of the performance loss is recovered. For example, bringing segmentation accuracy back up to 42 mIoU, i.e. recovering 82% of the original drop in accuracy.
Experience
PhD Student Jan 24 - Present | FAIR Paris & Sorbonne Univeristy Advisors: Loic Barrault, Patrick Gallinari, Benjamin Piwowarski
Research Scientist Intern Sep 22 - Feb 23 | FAIR Paris Advisors: Alaa El-Nouby, Jakob Verbeek
AI Research Intern Jul - Sep 21 | Unbabel Research Lisbon Advisors: Ricardo Rei, André Martins
Software Engineering Intern Jul - Sep 20 | Google Ads London Advisors: Yu Chen
Software Engineering Intern Jul - Sep 19 | Google Ads NY Advisors: Eric Duran
Software Engineering Intern Jul 18 | SAP Lisbon Advisors: Christian Franco
Hobbies
I am really into karting, and I am currently in an amateur karting league. Check out my team's YouTube channel () where we post about our races.
Amateur music production is something I also really like! I haven't publicly shared any of my music yet, but stay tuned...
Gaming, TV shows and movies is where I spend most of my free time, so feel free to reach out if you've got any suggestions!
Contact me
What's next? Feel free to reach out to me if you want to collaborate, or if you have any query about my research!

 Paris, France
●
Available for collaborations
Paris, France
●
Available for collaborations



















 )
)
